
0. 목차
Contents
1. 악성코드 식별
- 의심스러운 바이너리의 내용을 바탕으로 암호 해쉬 값을 생성하는 활동
- 파일명을 기준으로 악성코드 샘플을 식별하는 것은 동일한 악성코드 샘플이 다른 파일명을 사용할 수 있어 적합하지 않지만 파일 내용에 기반해 생성된 암호 해쉬는 이를 동일하게 식별하기 때문에 사용된다.
MD5,SHA1,SHA256과 같은 암호 해쉬 알고리즘은 악성코드 샘플의 파일 해쉬를 생성할 때 사실상 표준이며 암호 해쉬 알고리즘을 통해 얻은 해쉬 값으로 바이러스토탈과 같은 다중 백신 스캐닝 서비스의 데이터베이스에서 검색하여 이전에 탐지된 적이 있는지 판단할 수 있다.
1.1 해쉬 생성 툴을 이용하여 해쉬 값 생성
Linux)

windows)
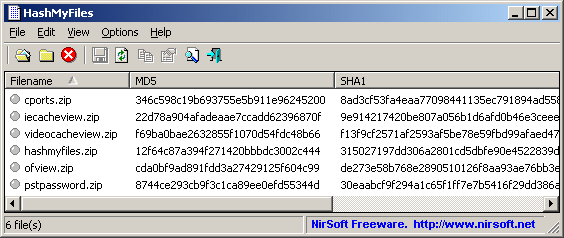
- 위 링크에서 HashMyFiles 설치

- 동일한 해시를 가지면 동일한 색깔로 강조됨
2. 다중 백신 스캐닝
- 다중 백신 스캐너에 의심스러운 바이너리를 올려 스캐닝하면 악성코드 시그니처가 존재하는지 확인할 수 있으며 시그니처 이름을 통해 파일과 그 기능에 대한 추가 정보를 얻을 수 있다. 이러한 작업은 분석 시간을 줄일 수 있는데 도움이 된다.
주의 사항)
- 의심 바이너리가 백신 스캐닝 엔진에 탐지되지 않았다고 해서 안전한 것은 아니다. 백신 엔진은 시그니처와 휴리스틱에 의존하기 때문에 악성코드 제작자가 자신의 코드를 살짝 수정하거나 난독화 기술을 통해 우회할 수 있다.
- 공개 사이트에 바이너리를 업로드하면 등록한 바이너리는 서드파티와 벤더에 공유될 수 있다. 이러한 정보는 민감하고 개인적이거나 소속 조직의 독점 정보가 포함될 수 있으므로 기밀 조사 중인 바이너리를 공개 백신 스캐닝 서비스에 등록하는 것은 권고하지 않는다. 따라서, 바이너리를 업로드하는 대신에 암호 해쉬 값(MD5, SHA1, SHA256)을 이용하여 검색할 수 있도록 한다.
- 온라인 백신 스캐닝 엔진에 바이너리를 등록하면 스캔 결과가 데이터베이스에 저장되고 이후에 공개적으로 조회할 수 있다. 공격자는 이를 통해 그들의 샘플이 탐지됐는지 확인하며 탐지된 경우 전략을 변경하거나 탐지를 회피할 수 있다.
2.1 웹 기반 악성코드 스캐닝 서비스(VirusTotal)
 http://www.virustotal.com
http://www.virustotal.com- 파일 업로드시 다양한 백신 스캐너로 스캐닝하고 실시간으로 스캔 결과 웹 페이지에 보여줌
- 공개 API 제공 → 스크립트를 작성할 수 있는 기능 제공(파이썬 2.7.x버전 사용)
APIVirusTotal's API lets you upload and scan files, submit and scan URLs, access finished scan reports and make automatic comments on URLs and samples without the need of using the HTML website interface. In other words, it allows you to build simple scripts to access the information generated by VirusTotal.
 https://support.virustotal.com/hc/en-us/articles/115002100149-API
https://support.virustotal.com/hc/en-us/articles/115002100149-API
2.2 PE 분석 도구(pestudio)

- 바이너리 로딩하면 바이너리의 해시 값을 바이러스토털 데이터베이스로 자동 질의 후 결과 출력
- 이외에도 해시값, 임포트 항목, string 등 기본 정적 분석시 필요한 기능 통합
3. 문자열 추출
- 문자열 추출은 프로그램 기능과 의심 바이너리 관련 지표에 대한 단서를 제공한다.
- 바이너리에서 추출한 문자열은 파일명, URL, 도메인명, IP주소 등을 포함할 수 있다.
- 문자열만 가지고는 파일의 목적과 기능에 대한 명확한 단서를 제공할 수는 없지만 악성코드가 할 수 있는 일에 대한 힌트를 제공할 수 있다.
3.1 도구를 이용한 문자열 추출
Linux)
- 리눅스 시스템에서 문자열 추출을 위해
strings유틸리티를 사용
strings명령어는 기본적으로 최소 4문자 이상인 ASCII문자열을 추출한다.
-a옵션을 주면 전체 파일에서 문자열을 추출할 수 있다.

- ASCII와 유니코드 문자열 모두 추출해야 할 때는
-el옵션을 사용strings는 ASCII문자가 아닌 문자는 판별을 못하므로-e(encoding)옵션을 지원한다. 예를 들어-e옵션에S를 붙여서(-eS) 사용하면UTF-8문자열을 검색한다.
Windows)
- 윈도우에서는 ASCII와 유니코드 문자열 모두 표현해주는 pestudio 사용

- pestudio는 blacklisted 열에 주요한 문자열 일부를 강조함으로써 분석을 돕는데 이를 통해 바이너리에서 유의미한 문자열에 집중할 수 있다.
3.2 FLOSS를 이용한 난독화된 문자열 디코딩
- 대부분의 경우 악성코드 제작자는 탐지를 회피하고자 간단한 문자열 난독화 기법을 사용한다. 이러한 경우는
strings와 같은 다른 추출 도구를 이용해 추출할 수 가 없다.
- FLOSS(FireEye Labs Obfuscated String Solver)는 악성코드에서 난독화된 문자열을 자동으로 추출하고 식별하고자 디자인된 도구이다. FLOSS를 통해 악성코드 제작자가 문자열 추출 도구를 피해 숨기고자 했던 문자열을 찾을 수 있도록 돕는다.
다운로드)

- 윈도우용, 리눅스용 FLOSS 있음
- FLOSS 결과에서 정적 문자열(ASCII와 유니코드)을 제외하고 디코딩/스택 문자열만 보고자 하는 경우엔
--no-static-string를 사용하면 된다.
(나중에 쓸 일 있으면 테스트 해봐야겠다. 성능 구대기라고는 했지만,,,)
4. 파일 난독화 파악
- 난독화 기술은 바이너리를 탐지 및 분석하기 어렵게 하기 때문에 추출할 수 있는 문자열은 별로 되지 않으며 문자열 대부분은 모호하다.
- 주로 백신과 같은 보안 솔루션의 탐지를 회피하고 분석을 방해하고자 패커(packer)와 크립터(crypter)같은 프로그램을 자주 사용한다.
4.1 패커와 크립터
① 패커
실행 파일을 입력으로 받아 실행 파일의 내용을 압축해 난독화하는 프로그램이다. 난독화한 콘텐츤느 새로운 실행 파일의 구조체에 저장된다. 디스크에 난독화된 콘텐츠를 담고 있는 새로운 실행파일(패킹한 프로그램)이 결과물로 생긴다. 패킹한 프로그램을 실행하면 압축해제 루틴이 실행되고 메모리에 원본 바이너리를 추출한 후 실행한다.
② 크립터
패커와 유사하지만 실행 파일의 내용을 난독화하고자 압축 대신 암호화를 사용한다. 암호화한 내용은 새로운 실행 파일에 저장한다. 암호화한 프로그램을 실행할 때 복호화 루틴을 실행해 원본 바이너리를 메모리에 추출한 후 실행한다.
패킹 탐지 툴)
- Exeinfo PE, DIE, PEID 등등..
5. PE 헤더 정보 조사
- PE헤더는 실행 파일이 메모리 어디에 로딩돼야 할지, 실행 파일의 시작이 어디인지, 애플리케이션이 의존하는 라이브러리 및 함수 목록, 바이너리가 사용하는 리소스와 같은 정보를 포함한다.
- PE헤더를 검사하면 바이너리와 그 기능의 풍부한 정보를 얻을 수 있다.
5.1 파일 의존성과 임포트 조사
- 일반적으로 악성코드는 파일, 레지스트리, 네트워크 등과 상호작용한다.
- 이런 상호작용을 수행하고자 악성코드는 운영 시스템에서 제공하는 함수를 많이 의존한다.
- 윈도우는 API함수를 임포트하고 있으며, 상호작용을 위해선 DLL파일이 필요로 한다.
- 따라서, 악성코드가 의존하고 있는 DLL과 그런 DLL이 임포트하고 있는 API함수를 조사하면 악성코드의 기능과 성능, 실행 중 예상할 수 있는 기능을 알 수 있다.

- [libraries]항목을 누르면 의존성을 가진 모든 DLL파일과 각 DLL에서 임포트한 임포트 함수의 수를 보여준다.
- 참고로, 실행 중 로드한 DLL의 정보는 나타나지 않는다.

- [imports] 항목을 누르면 DLL에서 임포트한 API함수를 표시한다.
추가적으로 임포트가 거의 없는 악성코드를 접할 경우 해당 파일이 패킹한 바이너리라는 사실을 바로 알 수 있는데 도움을 준다.
UPX 패킹 전)

- [imports] 항목에 총 75개의 API함수가 import되어 있음
UPX 패킹 후)

- [imports] 항목에 총 5개의 API함수가 import되어 있음
5.2 익스포트 조사
- 실행 파일과 DLL은 다른 프로그램에서 사용할 수 있는 함수를 익스포트할 수 있다.
- 일반적으로 DLL은 실행 파일이 임포트할 수 있는 함수(익스포트)를 노출하며 DLL은 단독으로 실행할 수 없기 때문에 호스트 프로세스를 통해 실행한다.
- 공격자는 악의적인 함수를 익스포트하는 DLL을 자주 생성한다.
- DLL에 있는 악의적인 함수를 실행하고자 어떻게 해서든지 프로세스가 이 함수를 로딩하도록 한다. 따라서, 익스포트 함수를 조사하면 DLL의 기능을 빠르게 이해할 수 있다.

- Reflective DLL Injection에서 사용되는 Reflective DLL의 ReflectiveLoader함수가 export에 있는 것을 확인
주의)
- 익스포트 함수명이 매번 악성코드의 기능에 대해 힌트를 제공하는 것은 아니다. 공격자는 분석가를 잘못된 방향으로 이끌거나 추적하지 못하도록 랜덤 또는 가짜 익스포트명을 사용할 수 있다.
5.3 PE 섹션 테이블과 섹션 조사
- 섹션은 PE 헤더 바로 다음에 존재하며 PE 파일의 실제 내용은 섹션으로 구분한다.
- 섹션 명은 사람을 위한 것으로 운영 시스템에서는 사용되지 않는다. 이는 공격자 또는 난독화 소프트웨어가 섹션명을 다른 이름으로 변경할 수 있음을 의미한다.
- 따라서, 일반적이지 않은 섹션명을 접할 경우 의심의 여지를 두고 분석하여 악성 여부를 확인해야 한다.
- 또한, 섹션 테이블 검사는 PE 파일의 이상을 식별하는데에도 도움을 준다.

- 위 사진을 보면
EntryPoint가UPX1에 있으며 이는 이 섹션에서 실행이 시작한다는 것(압축 해제 루틴)을 나타낸다.
- 또한, 일반적으로
raw-size와virtual-size가 거의 같아야 하지만, 위UPX0를 보면raw-size가 0이지만virtual-size는 이보다 더 큰 공간인 69kb를 갖고 있음을 나타낸다.
- 이는 패킹한 바이너리란 사실을 강하게 나타내며 이러한 불일치가 존재하는 이유는 패킹한 바이너리를 실행할 때 패커의 압축 해제 루틴이 런타임 중 압축 해제한 데이터 또는 명령어를 메모리로 복사하기 때문이다.
5.4 컴파일 타임스탬프 조사
- PE헤더의 타임스탬프 필드는 바이너리가 컴파일될 때 생성되는 정보를 포함한다.
- 이 필드를 조사하면 악성코드가 언제 처음 생성되었는지 알 수 있으며 해당 정보를 통해 공격 활동의 타임라인을 작성할 때 도움을 준다.

(하지만, 공격자가 실제 타임스탬프를 알 수 없도록 수정해 분석을 방해할 수도 있다.)
타임스탬프는 의심스러운 샘플을 분류할 때도 가끔 사용하는데 예를 들면 미래 시간을 타임스탬프로 수정한 경우이다. 이러한 경우 실제 컴파일 타임스탬프를 알 수 없더라도 이런 특징은 비정상적인 행위를 식별하는데 도움을 준다.
5.5 PE 리소스 조사
- 아이콘, 메뉴, 대화상자, 문자열과 같이 실행 파일에 필요한 리소스는 실행 파일의 리소스(.rsrc)에 저장한다.
- 때때로 공격자는 추가 바이너리 및 문서, 설정 데이터 같은 정보를 리소스 섹션에 저장하므로 리소스를 조사함으로써 바이너리에 관련된 의미 있는 정보를 찾을 수 있다.
- 근원지, 회사명, 프로그램 제작자 세부 정보, 저작권 관련 정보를 노출할 수 있는 버전 정보도 포함한다.
Resource Hacker 설치 및 확인)
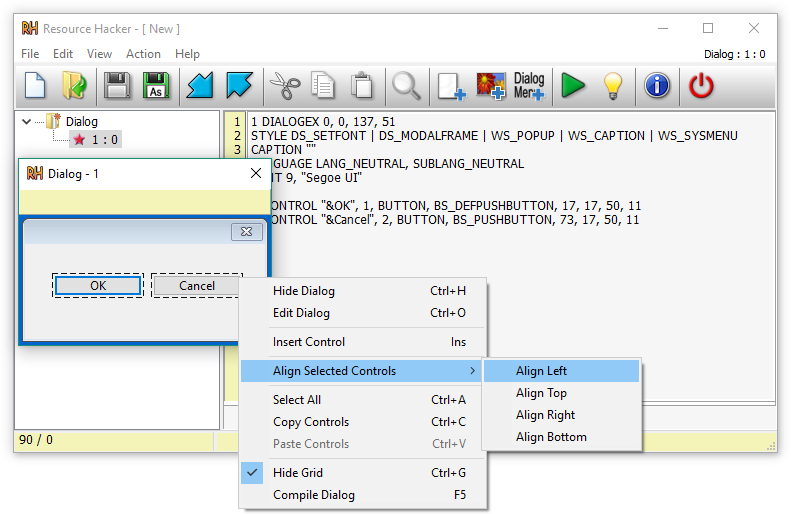

- 해당 파일에 리소스 섹션이 존재하며 실행가능한 파일이 있음을 확인

- PE파일 시그니쳐 통해 추가로 리소스 섹션에 PE파일이 존재함을 확인

- 리소스 섹션에 저장된 파일을 추출할 수도 있음
6. 악성코드 비교와 분류
악성코드를 조사하는 중에 악성코드 샘플을 발견하면 해당 악성코드 샘플이 어떤 악성코드 군에 속하는지 또는 이전에 분석한 샘플과 일치하는 특징을 갖는지 궁금해 할 수 있다.
의심 바이너리를 이전 분석 샘플 또는 공개, 사설 저장소에 저장된 샘플과 비교하면 악성코드군, 악성코드의 특징, 이전 분석 샘플과의 유사성을 파악할 수 있다.
암호 해시(MD5, SHA1, SHA256)는 일치하는 샘플을 찾는 좋은 기술이지만 유사한 샘플을 식별하는데는 도움되지 않는다. 악성코드 제작자는 빈번하게 악성코드의 미세한 부분을 변경해서 해시 값을 완전히 변형하기 때문이다.
6.1 퍼지 해싱을 이용한 악성코드 분류
- 퍼지 해싱(fuzzy hashing)은 파일 유사도를 비교하는 좋은 방법이다.
Fuzzy Hash
- 기존 Hash의 무결성 확보뿐만 아니라 원본 파일과의 유사도 파악
- 파일 전체에 대한 해쉬 값을 계산하지 않고, 일정 크기 단위로 구분하여 각 단위 블록에 대한 해쉬 값을 만들어내는 방식
- 각 영역의 마지막 몇 바이트에 대한 해쉬 값을 이용하여 체크섬 데이터를 만든 후 유사도를 비교
ssdeep
- ssdeep는 샘플에 대한 퍼지 해시를 생성하는 도구
- 샘플 간의 유사성 비율을 파악하는데에 도움을 준다.
- 이 기술은 의심 바이너리와 저장소의 샘플들을 비교해 유사한 샘플을 식별하는데 유용
- 동일한 악성코드군 또는 동일한 공격자 그룹에 속하는 샘플을 식별하는데 도움을 준다.
윈도우에서 ssdeep 설치)

우분투에서 ssdeep 설치)
$sudo apt-get update -y $sudo apt-get install -y ssdeep
ssdeep 테스트)
테스트 코드로 다음과 같이 작성하고 빌드
[ sample_A.c ]
#include <stdio.h> #include <stdlib.h> int main(){ int a; printf("hi\n"); return 0; }
[ sample_B.c ]
#include <stdio.h> int main(){ int i = 99; printf("hi\n"); while(i > 0){ i -= 1; } return 0; }
두 코드는 최종적으로 "hi"를 출력만 해주며 sample_B에서는 일부러 의미 없는 코드를 넣었다.

- MD5 해쉬 값을 비교한 결과 다른 결과가 나오게 된다.

- 각 파일의 퍼지 해시를 확인하려면
ssdeep [filename]을 입력하면 된다.
ssdeep에 있는 상세 일치 모드 -p옵션을 사용해 유사도 확인

- 퍼지 해시 비교 결과 sample_A와 sample_B사이에 75%의 유사도를 가진다.
추가 1)
많은 악성코드 샘플이 포함된 디렉터리가 존재하는 경우 -r(재귀 모드)옵션을 사용해 디렉터리와 악성코드 샘플을 포함한 하위 디렉터리에서 ssdeep를 실행할 수 있다.
$ssdeep -lrpa [dir]/
추가 2)
의심 바이너리를 파일 해시 목록과 비교할 수 있다. 모든 바이너리의 ssdeep 해시를 텍스트 파일로 리다이렉션하여 저장하고 의심 바이너리는 파일에 있는 모든 해시와 비교한다.
$ssdeep * > all_hashes.txt $ssdeep -m all_hashes.txt [의심 바이너리 파일]
6.2 임포트 해시를 이용한 악성코드 분류
임포트 해싱(import hashing)은 연관성 있는 샘플과 동일한 공격자 그룹에서 사용한 샘플을 식별하는 데 사용할 수 있는 다른 기술이다.
임포트 해시(import hash, imphash)
- 실행 파일에 있는 라이브러리 및 임포트 함수(API)명과 특유의 순서를 바탕으로 해시 값을 계산하는 기술
- 동일한 소스와 동일한 방식으로 파일을 컴파일할 경우 해당 파일은 동일한
imphash값을 갖는 경향이 있다.
이러한 imphash값은 pestudio에서 확인할 수 있다.

Python을 이용하여 구현)
import pefile import sys pe = pefile.PE(sys.argv[1]) print pe.get_imphash()
관련 내용)

- 임포트 해싱 관련 상세 정보와 어떻게 위협 공격자 그룹을 추적할 때 사용할 수 있는지에 관한 내용
 https://blogs.jpcert.or.jp/ja/2016/05/impfuzzy.html
https://blogs.jpcert.or.jp/ja/2016/05/impfuzzy.html
- 임포트 API와 퍼지 해싱기술을 사용해 악성코드 샘플을 분류하는 방법에 관한 내용
주의할 점)
동일한 imphash를 가진 파일이 반드시 동일한 위협 그룹으로부터 만들어졌다는 것을 의미하지는 않는다. 다양한 소스의 정보를 상호연관시켜 악성코드를 분류해야 할 수 있다. 예를 들어 그룹 간에 공유하는 공통 빌더 키트(builder kit)를 사용해 악성코드 샘플을 생성할 수 있다. 이런 경우 샘플은 동일한 imphash를 가질 수 있다.
6.3 섹션 해시를 이용한 악성코드 분류
임포트 해시와 유사하게 섹션 해싱(section hashing)도 관련 샘플을 식별하는 데 도움을 줄 수 있다.
섹션 해시도 임포트 해시와 동일하게 pestudio를 통해 확인할 수 있다.

Python을 이용하여 구현)
import pefile import sys pe = pefile.PE(sys.argv[1]) for section in pe.sections: print "%s\t%s" % (section.Name, section.get_hash_md5())
6.4 YARA를 이용한 악성코드 분류
악성코드 샘플은 많은 문자열 또는 바이너리 구분자를 포함할 수 있다. 고유 악성코드 샘플 또는 악성코드군을 인식하면 악성코드 분류에 도움이 된다. 따라서, 바이너리에 나타나는 고유 문자열과 바이너리 구분자를 기준으로 악성코드를 분류하며 경우에 따라 악성코드를 일반적인 특성에 따라 분류하기도 한다.
YARA
- 악성코드 샘플에 포함된 패턴을 이용해 특성과 행위를 기준으로 악성 파일을 분류하는데 사용되는 툴이다.
- 악성코드 샘플에 포함된 텍스트 또는 바이너리 정보를 기반해 YARA Rule을 생성할 수 있다.
- YARA Rule은 로직을 결정하는 문자열과 부울 표현식의 집합으로 구성되며 YARA Rule을 작성하면 YARA 유틸리티 또는 yara-python을 사용해 작성한 도구로 파일을 스캐이할 때 해당 규칙을 이용할 수 있다.
- VirusTotal에서 제작되었으며 오픈소스로 관리되고 있다.(구글에서 코드 관리)
- YARA를 사용하고 있는 주요 서비스 및 제품에는 VirusTotal, malwares.com, FireEye가 있다.
장점)
- 비교적 간단한 문법의 YARA Rule을 작성하는 것만으로도 악성코드의 샘플이 특정 기능을 하는지 명시된 조건이 포함되어 있는지 여부 확인
- 단순히 Text String이나 Binary 패턴을 이용하여 시그니쳐(Signature)를 찾는 것 뿐만 아니라 특정 Entry Point값을 지정하거나, File Offset, 가상 메모리 주소를 제시하고, 정규표현식을 이용하는 등의 검색방식을 가능하게 함으로써 효율적인 패턴 매칭 작업이 가능하다.
- 오픈 소스이며 Linux, MAC, Windows에서도 사용가능하다.(멀티 플랫폼)
단점)
- YARA는 시그니쳐 탐지 방식의 한계 존재(시그니쳐 외의 공격에 대해서는 탐지를 못하는 한계가 있다.)
YARA 관련 참고 자료)
 https://m.blog.naver.com/PostView.nhn?blogId=yayayago&logNo=220078545611&proxyReferer=https:%2F%2Fwww.google.com%2F
https://m.blog.naver.com/PostView.nhn?blogId=yayayago&logNo=220078545611&proxyReferer=https:%2F%2Fwww.google.com%2F
1) YARA 설치하기
linux)
$sudo apt-get install -y yara
이외의 다른 시스템)
2) YARA 규칙 기초
특정 문자열을 찾는 간단한 YARA 규칙 예제를 통해 구성을 살펴보자
[ suspicious.yara ]

컴포넌트 구성)
① 규칙 식별자(rule identifier)
- 규칙을 설명하는 이름이다.(위 예에서는 suspicious_strings)
- 영문자, 숫자, 밑줄을 포함할 수 있지만 첫 번째 문자로 숫자를 사용할 수 없다.
- 대소문자를 구분하며 128자를 초과할 수 없다.
② 문자열 정의(string definition)
- 규칙의 일부인 문자열(텍스트, 16진수 또는 정규표현식)이 정의되는 섹션(변수로 생각하면 됨, 조건 섹션에서 사용됨)
- 규칙이 문자열에 의존하지 않을 경우 생략할 수 있다.
- 각 문자열은 연속된 영문자, 숫자, 밑줄이 뒤따르는 $문자로 구성된 식별자를 갖는다.
③ 조건 섹션(condition section)
- 선택 섹션이 아니며, 규칙의 로직이 위치하는 곳
- 이 섹션에 규칙이 일치하거나 일치하지 않는 조건을 지정하는 부울(bool) 표현식을 포함해야 한다.
위 규칙은 $a, $b, $c에 정의된 세 문자열이 파일 내에 하나라도 존재하면 일치하는 것을 의미한다. 이제 yara 툴을 실행시켜보자
3) YARA 실행
테스트 코드로 다음과 같이 작성하고 빌드하자
[ sampleA.c ]
#include<stdio.h> int main(){ printf("Synflooding\n"); return 0; }
- 실행 결과 "Synflooding"문자열이 탐지되었다고 나온다.
그럼 만약에 동일하게 "Synflooding"문자열을 출력하는 프로그램인데 코딩을 조금만 다르게 하고 실행시키면 어떻게 될까?
[ sampleB.c ]
#include<stdio.h> int main(){ printf("Synfl"); printf("ooding\n"); return 0; }
- 탐지되지 않는다... 이 부분이 바로 위에서 언급했던 Yara의 단점이다.
- 만일, 어떤 멀웨어 A는 탐지되었지만 동일한 기능을 수행하는 멀웨어 B는 내부 코드가 조금 달라 탐지되지 않을 수 있는 것이다.
이제 yara룰에 적용되는 추가 옵션들을 살펴보자
Example 1)

- ASCII와 유니코드(와이드 문자) 문자열을 탐지하는 규칙을 추가하려면
ascii와wide수식어를 지정한다.
- 대소문자를 구분하지 않는 매칭을 추가하려면
nocase수식어를 지정한다.
실행결과)

Example 2)

- 실행 파일에 국한해 문자열을 찾기 위해서라면 위 빨간색 박스처럼 만들어준다.
$mz at 0은 YARA가 파일이 시작되는 곳에서4D 5A시그니쳐를 찾도록 지정하는 것이다.
- 텍스트 문자열은 더블 쿼터로 묶어주는 반면 16진수 문자열은 중괄호로 묶는다.
실행결과)

+) 추가로 -r 옵션을 주면 리컬시브하게 하위 디렉토리에 있는 파일들까지 다 검색한다.
Example 3)
UPX 패커를 탐지할 때 사용하는 시그니쳐 포맷을 사용하여 yara rule을 작성

새로운 버전의 yara는 PE파일 포맷의 속성과 기능을 사용해 PE파일을 위한 규칙을 생성할 수 있는 PE모듈을 지원

규칙에 사용한 문자열이 오탐(false positive)을 유발할 수 있으므로 알려진 정상 파일을 대상으로 테스트하고 오탐을 유발할 수 있는 상황을 생각하는 것이 좋다.
4) References
 https://www.nextron-systems.com/2015/02/16/write-simple-sound-yara-rules/
https://www.nextron-systems.com/2015/02/16/write-simple-sound-yara-rules/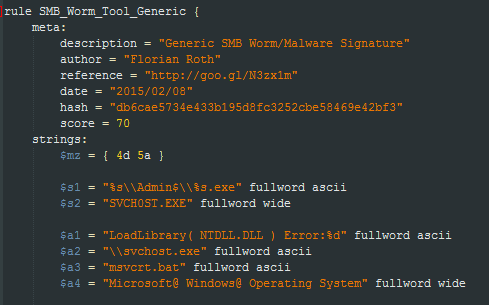




Uploaded by Notion2Tistory v1.1.0